Cloud setup
Concept
Deze pagina beschrijft op summiere wijze hoe Skryv applicaties voorbereid, opgezet en gedeployed kunnen worden. Onderstaande beschrijving gaat uit van een deployment in een AWS cloudomgeving. Weet dat het ook mogelijk is om de applicatie te hosten op een andere cloudomgeving (bijvoorbeeld Azure) of lokaal op een pc of server.
De opzet en deployment van de applicatie worden inhoudelijk voorbereid volgens het Infrastructure as Code (IaC)-principe. Hiervoor gebruiken we Terraform-bestanden die in de application repository beheerd worden. Houd bij het uitwerken van deze configuraties rekening met onze best practices om consistentie en veiligheid te waarborgen.
Deze pagina is bedoeld als high-level referentiedocument voor ontwikkelaars en DevOps-engineers. Voor concrete stap-voor-stap begeleiding bij het opzetten van een nieuwe omgeving, neem je contact op met het Skryv team.
Voor informatie over het dagelijkse operationele beheer (upgrades, monitoren, incidenten) van een reeds uitgerolde Skryv applicatie, zie Cloud beheer.
Cloud omgeving voorbereiden
Vooraleer een nieuwe applicatie op te zetten, moet eerst de AWS Cloudomgeving worden aangemaakt en voorbereid. Dit vormt de basis waarop de applicatie en alle bijhorende componenten (zoals databases, opslag en netwerkverbindingen) zullen draaien. Globaal gezien omvat dit de volgende stappen:
AWS-account aanmaken en configureren
Netwerk en beveiliging configureren
Opslag en databases voorzien
Compute resources opzetten
Monitoring en logging activeren
OTAP-omgevingen opzetten (ontwikkeling, test, acceptatie, productie)
CI/CD-integratie met Jenkins instellen
…
Zie ook de pagina Wat is een Skryv applicatie? voor een overzicht van alle componenten.
Setup AWS-cloudomgeving via Terraform
Voor de setup van de AWS-cloudomgeving worden Terraform-bestanden gebruikt om de benodigde infrastructuur te definiëren, zoals servers, netwerken, containers en opslag. Daarbij hanteren we een aantal richtlijnen en afspraken om herbruikbaarheid en voorspelbaarheid te garanderen.
Modules per applicatie, niet generiek
We verkiezen Terraform‑modules die specifiek zijn voor één applicatie boven generieke modules die over alle Skryv applicaties heen worden gedeeld. We definiëren dus modules in de repository van de applicatie zelf en stellen daarbij enkel die variabelen bloot die effectief moeten verschillen tussen omgevingen (bijvoorbeeld tussen ontwikkeling, test, acceptatie en productie). We streven er dus naar om zo weinig mogelijk variabelen te hebben: hoe minder variabelen, hoe gelijkvormiger en voorspelbaarder de omgevingen zijn.
Start vanuit Terraform, niet vanuit de AWS‑console
Nieuwe infrastructuur wordt in principe eerst in Terraform gedefinieerd en pas daarna uitgerold. De AWS‑console is dus ondersteunend, niet leidend.
Redenen hiervoor:
Infrastructure as a Code (IaC) benadering zorgt voor meer controle en minder fouten.
Het is vaak overzichtelijker om de Terraform AWS-documentatie te raadplegen dan om door de AWS‑console te klikken.
De AWS‑console toont niet altijd alle mogelijke configuratieopties die de service ondersteunt. Wie eerst “even snel” via de UI klikt en dat nadien probeert terug te brengen naar Terraform, kan voor onaangename verrassingen komen te staan.
Voor een snelle verkenning van een nieuwe AWS‑service mag de UI uiteraard gebruikt worden, maar de definitieve configuratie verwerken we steeds in Terraform.
Remote state gebruiken (behalve voor de state‑stack zelf)
Terraform werkt in essentie als een state machine: het vergelijkt de gewenste toestand (configuratie) met de huidige toestand (state) en voert op basis daarvan acties uit.
Een algemeen best practice‑patroon is om een S3‑bucket te gebruiken als remote state backend, en een DynamoDB‑tabel te gebruiken voor state‑locking.
Dit brengt echter een klassiek “chicken‑and‑egg‑probleem” mee: wie maakt deze remote state‑resources zelf aan, en in welke state worden die dan opgeslagen?
Onze aanpak: we maken de S3‑bucket en DynamoDB‑tabel wél met Terraform aan. De Terraform‑state van deze specifieke ‘state‑stack’ bewaren we niet in de remote state zelf, maar in de repository (lokale state die in git wordt beheerd).
Zo hebben we wél Infrastructure as Code (IaC) voor de remote state‑resources, zonder de complexiteit en cirkelredenering van een remote state die zijn eigen fundamenten bevat. Alle andere stacks gebruiken wél de remote state backend.
Provider‑versies expliciet vastzetten
Voor de AWS‑provider zetten we de versie expliciet vast op de laatste minor binnen een gekende major‑versie.
Voorbeeld
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}Dit zorgt ervoor dat we automatisch bugfixes en kleinere verbeteringen binnen dezelfde major‑versie meekrijgen en dat we niet onverwacht worden geconfronteerd met breaking changes van een nieuwe major‑versie. Hetzelfde principe geldt bij voorkeur ook voor andere kritieke providers.
Lock‑bestanden genereren voor alle relevante platformen
Terraform gebruikt een lock‑bestand (.terraform.lock.hcl) om provider‑versies én hun checksums te vergrendelen. In omgevingen waar Terraform‑scripts zowel lokaal (bijvoorbeeld op Macs met M1‑processor) als in CI/CD‑pipelines (meestal op AMD64‑linuxagents) worden uitgevoerd, kan dit problemen geven. Als het lock‑bestand alleen checksums voor ARM bevat (bv. macOS op Apple Silicon), zullen terraform plan en terraform apply in een AMD64‑pipeline falen. Om dit te vermijden, genereren we lock‑bestanden met checksums voor alle relevante platformen.
Voorbeeld
terraform init && terraform providers lock -platform=linux_amd64Indien nodig kunnen meerdere -platform‑waarden worden opgegeven, zodat zowel lokale ontwikkelomgevingen als CI/CD‑agents ondersteund worden.
Geen branches voor live infrastructuur
Branches worden gebruikt om wijzigingen te ontwikkelen en te reviewen, niet om live infrastructuur te representeren.
Concreet:
we gebruiken géén aparte git‑branch per omgeving (bv.
dev,test,acc,prod) waarvan elke branch een eigen “live” infrastructuurtoestand zou voorstellen;het dupliceren van modules over verschillende environment‑branches of het delen van modules vanuit één aparte branch maakt het beheer complex en foutgevoelig.
In plaats daarvan:
branches worden enkel gebruikt om een
terraform planuit te voeren en te tonen wat Terraform zou doen;de effectieve wijzigingen (
terraform apply) gebeuren pas nadat de code is gereviewd en gemerged naar de hoofdbranch (bijvoorbeeldmasterofmain);de omgeving (dev, test, acc, prod, …) wordt bepaald door variabelen, workspaces of afzonderlijke stacks, niet door git‑branches.
Applicatie provisioning en deployment
High-level beschrijving
De uiteindelijke Terraform‑configuraties worden door een CI/CD‑tool, zoals Jenkins, uitgevoerd. Na expliciete goedkeuring (code‑review en goedgekeurd plan) voert de pipeline de benodigde terraform apply‑stappen uit, zodat de gewenste AWS‑resources automatisch worden ingericht op basis van de bronconfiguratie in git. Tijdens de build‑ en deployfase van de applicatie worden op basis van de Maven‑dependencies (gedefinieerd in pom.xml) de vereiste libraries opgehaald uit de Skryv‑Artifactory.
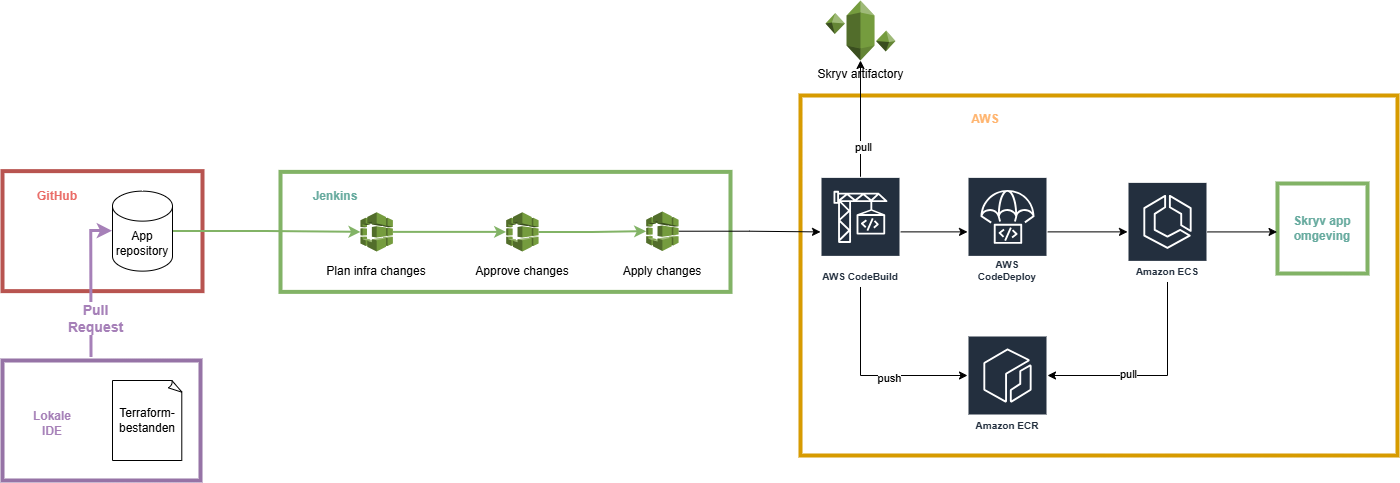
Pipelines
Pipelines zijn geautomatiseerde workflows die de stappen van softwareontwikkeling, zoals bouwen, testen en deployen, achter elkaar uitvoeren om een snelle en betrouwbare release van applicaties te garanderen. Voor een Skryv applicatie hebben we in Jenkins typisch twee aparte pipelines uitgewerkt, elk met een eigen finaliteit.
De provisioning-pipeline is de meest ingrijpende en wordt enkel gebruikt bij update van kritieke infrastructuurcomponenten. Hierbij wordt de dienstverlening tijdelijk offline gehaald.
De deployment-pipeline vergt geen onderbreking van de dienstverlening en is van toepassing bij het updaten van services of configuratiebestanden.
Provisioning-pipeline | Deployment-pipeline |
|---|---|
Omgevingsvariabelen | Applicatie code |
Database | Communicatie templates |
Netwerk | Formulierdefinities |
Load balancer | BPMN & DMN bestanden |
ElasticSearch | Backend of frontend code |
Concrete tips
Bij het reviewen en applyen van een Terraform-plan moet je letten op de volgende symbolen.
Symbool | Uitleg | Uitleg |
|---|---|---|
+ | will be created | Dit zal nieuw aangemaakt worden. |
- | will be destroyed | Dit zal verwijderd worden. |
~ | will be modified in-place | Bestaande zal aangepast worden. |
-/+ | will be destroyed and recreated | Zal verwijderd en opnieuw aangemaakt worden. |
<= | will be read | Zal gelezen worden. |
Wat zijn zogenaamde ‘red flags’ waar je op moet letten?
Wijzigingen aan VPC, subnets of core netwerkconfiguratie.
+/- (destroy and recreate) bij databases, clusters en load balancers.
- (destroy) van zaken die je niet bewust wil verwijderen.
Groot aantal wijzigingen, terwijl je er slechts ééntje verwachtte.
Gewijzigde benaming van resources (triggert verwijdering en opnieuw aanmaken).
Wijzigingen in versienummers.
Detail instructies
Neem contact op met het Skryv team voor gedetailleerde instructies en toegang tot de juiste repositories.