Omgaan met data in processen
Vooraf
Het doel van de meeste Skryv applicaties is het samenstellen van een dossier op basis van data die je op een procesmatige manier verzamelt. In deze sectie staan we stil bij hoe data doorheen de applicatie stroomt. We duiden enkele aandachtspunten en stellen best practices voor.
Van externe bron tot dossierinfo
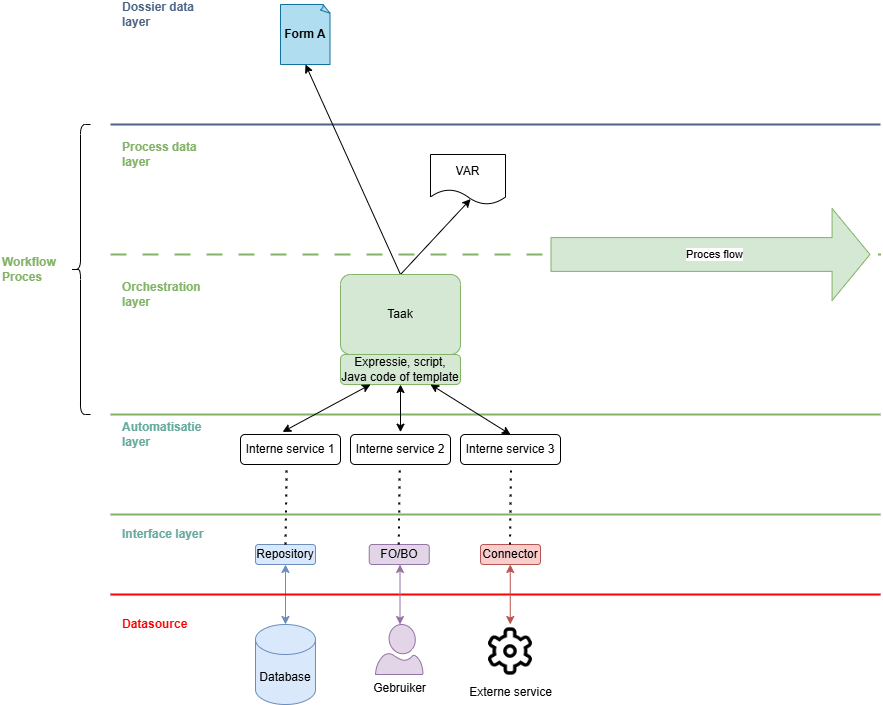
Binnen de applicatie heb je een verticale en een horizontale dimensie:
Verticaal: informatie stroomt verticaal van een datasource (database, gebruiker, service) via een interface (repo, FO/BO, connector) en een stuk code (interne service) naar de proceslaag en uiteindelijk naar het dossier.
Horizontaal: de informatie die binnen de scope van het proces wordt gebracht, stroomt ook horizontaal en leeft dus binnen de scope van het volledige proces.
Enkele belangrijke vuistregels
Verticale stroom
Laat enkel de hoogstnoodzakelijke data doorstromen naar het proces en het dossier. Informatie stijgt op vanuit de datasource via de interfacelaag naar de automatisatielaag. Binnen de interne services vang je de informatie op middels variabelen. By default ga je ervanuit dat je de data enkel maar lokaal binnen de service nodig hebt. Geef dus enkel die informatie naar boven door die echt noodzakelijk is binnen het dossier of binnen het proces (bijvoorbeeld om een gateway aan te sturen).
Waarom?
Privacy-gevoelige data uit het proces houden (en dus de nood aan anonymisatie voorkomen).
Moeilijkheden vermijden bij migratie van variabelen of formulieren na nieuwe versie proces of formulierdefinitie (zie ook sectie omtrent backwards compatibility).
Minder formulieren en procesvariabelen leidt tot beter overzicht.
Horizontale stroom
Hou de procesdata die horizontaal stroomt zo beperkt mogelijk.
Waarom?
Broze dependencies vermijden tussen formulieren onderling en/of procesvariabelen.
Data raakt out-of-sync met de datasource naarmate het proces voortschrijdt.
Proces als orchestratielaag
Het biedt voordelen wanneer je een proces zo ‘licht’ mogelijk houdt, d.w.z. gebruik het zo weinig mogelijk om data te manipuleren. Het proces uitgevoerd binnen de workflow engine is er in de eerste plaats om te orchestreren.
Voorbeeld
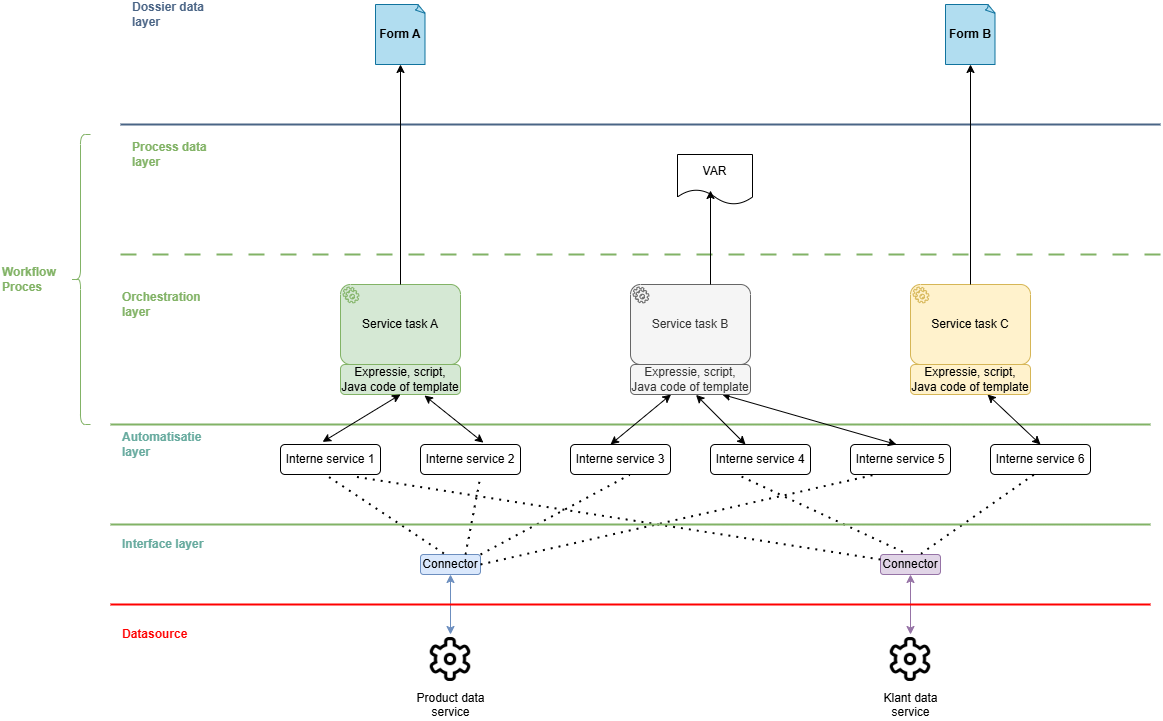
Proces mét alle data upfront ingeladen
Proces waarbij we in een vroeg stadium de data inladen. We kopiëren alle informatie omtrent het product en de klant naar formulieren en procesvariabelen.
Hieronder zie je schetsmatig wat er gebeurt wanneer we alle data via een eerste service task in een formulier en/of procesvariabelen kopiëren. De data blijft gedurende het volledige proces leven in de bovenste twee lagen. Het voordeel hiervan is dat je alles dicht bij de hand hebt. Nadeel is dat je met een kopie aan het werken bent. Zeker bij langlopende processen bestaat het risico dat je out-of-sync geraakt met de echte databron. Een tweede nadeel is dat veel data privacy-gevoelig is. Deze moet je dus achteraf terug gaan verwijderen (zie sectie rond anonymisatie). Tot slot zijn variabelen en formulierdata lastig om te migreren wanneer je een nieuwe versie van je proces of van je formulierdefinitie wil pushen (zie sectie rond backwards compatibility).
Merk trouwens op dat hetzelfde geldt voor informatie afkomstig vanuit een frontoffice of backoffice gebruiker of een zelf opgezette databank.
Bijvoorbeeld, als je bij de start van het proces aan een frontoffice gebruiker vraagt wat zijn of haar precieze gewicht is, dan is dat een momentopname. Op het einde van het proces, enkele maanden later, is die informatie alweer achterhaald en kan die persoon enkele kilo’s bijgekomen of afgevallen zijn.
Bijvoorbeeld, als je via de Magda connector informatie opvraagt over een burger, dan kan deze informatie na verloop van tijd out-of-date raken. De burger is pakwag verhuisd, gehuwd, heeft een tweede woning gekocht, enzovoort.
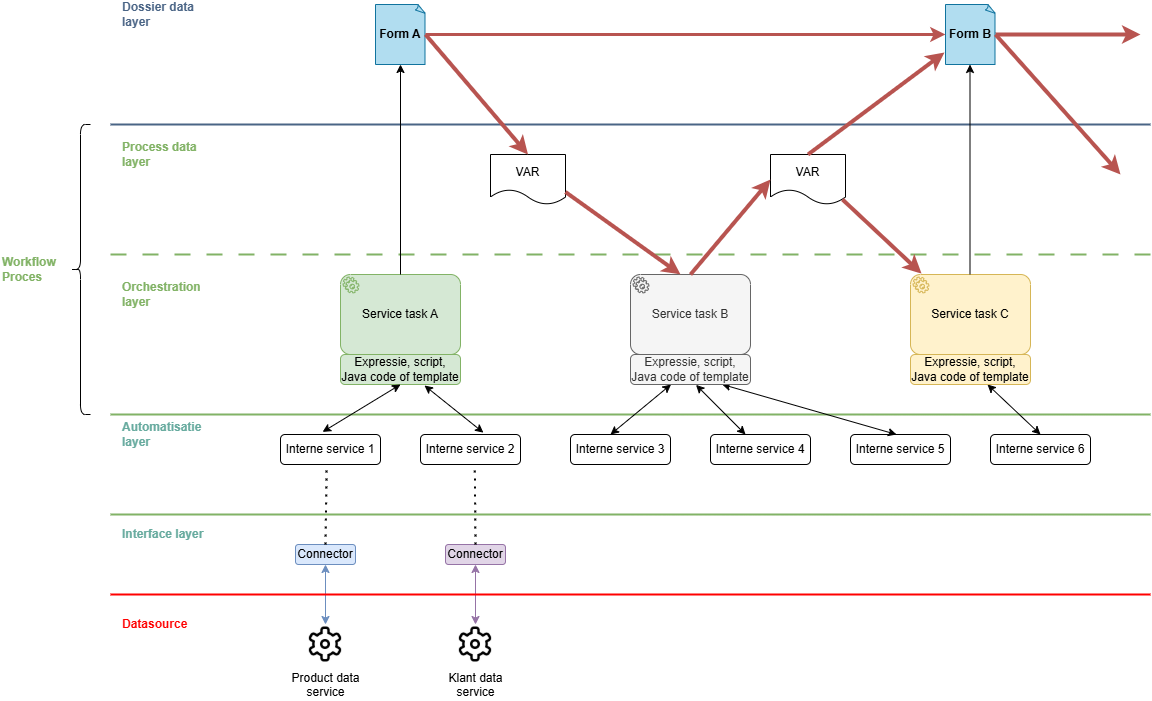
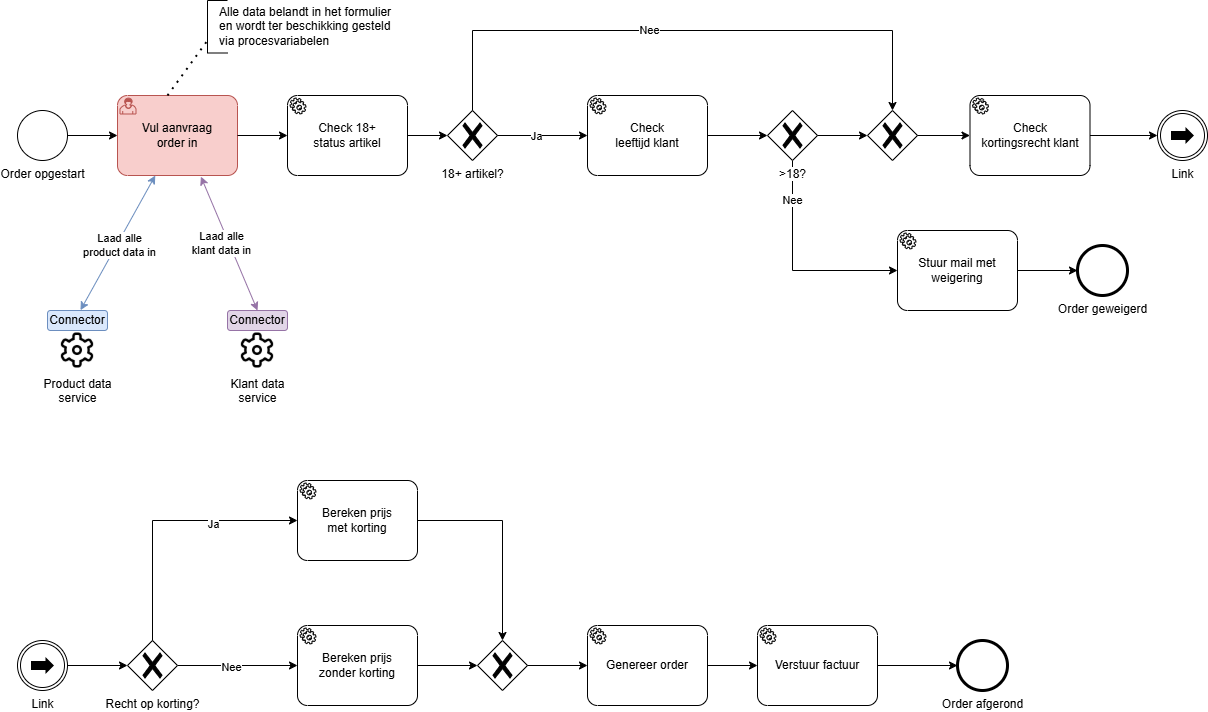
Proces met just-in-time data
Proces waarbij we de data niet in één keer upfront, maar verspreid over het volledige proces inladen. Bijzonder is ook dat we bij elk stapje slechts de informatie opvragen die strikt noodzakelijk is binnen die stap. De juiste data op het juiste moment op de juiste plaats, dus.

Hieronder zie je hoe we via deze aanpak de bovenste twee lagen veel minder hoeven te benutten. Eerst en vooral komt daar enkel informatie die strikt noodzakelijk is binnen het proces (zoals een variabele die een gateway moet sturen) of binnen het dossier. Veel van de opgevraagde informatie hoeft zelfs nooit het proces te bereiken, maar wordt gewoon lokaal binnen een specifieke service opgevraagd en daar direct geconsumeerd. Verder hou je op die manier meer privacy-gevoelige data uit het proces en verzacht je ook de migratieproblematiek bij het pushen van een nieuwe versie van het proces of van je formulierdefinities.